
No Fight, No Chance: Security Teams Must Become Hybrid AI Teams
The Ledger Donjon's journey from AI-assisted development to an AI security harness, and why offense is no longer only the best defense, but a required security capability.
Key Takeaways
- AI is changing the economics of offensive security: more scale, lower cost, and faster iteration for attackers.
- AI coding assistants are useful, but they are not enough to detect and verify security issues at scale.
- A prompt is not an agent. Real agents need iteration loops, memory, tools, task management, auditability, and constraints.
- Agentic security systems are still software systems: cost, scalability, resilience, and non-determinism must be engineered.
- The goal is not to replace security experts. The goal is to give them a team of agents that can explore, challenge, verify, patch, and learn with them.
Over the last few months, the Ledger Donjon has not only been watching the AI wave from the side. We have been transforming the way we work into something closer to a hybrid human and AI security team.
The first signals were easy to dismiss. A flood of low-quality AI-generated bug bounty submissions here. A few spectacular announcements about AI models finding vulnerabilities there. A lot of noise, a few real results, and many people waiting for the next frontier model as if access to the model alone would solve everything.
That is the wrong conclusion.
You should not wait. And the model alone is not enough.
AI dramatically increases the offensive capacity available to attackers. It reduces costs. It increases scale. It automates exploration. It lowers the barrier to entry. It also creates noise, but buried inside the noise there will be real vulnerabilities, real exploits, and real attackers who know how to use these systems properly.
So security teams have no choice. They must prepare, arm themselves, and use AI as an ally to create or extend their own offensive capabilities.
This is the story of how we started building an AI security harness at Ledger.
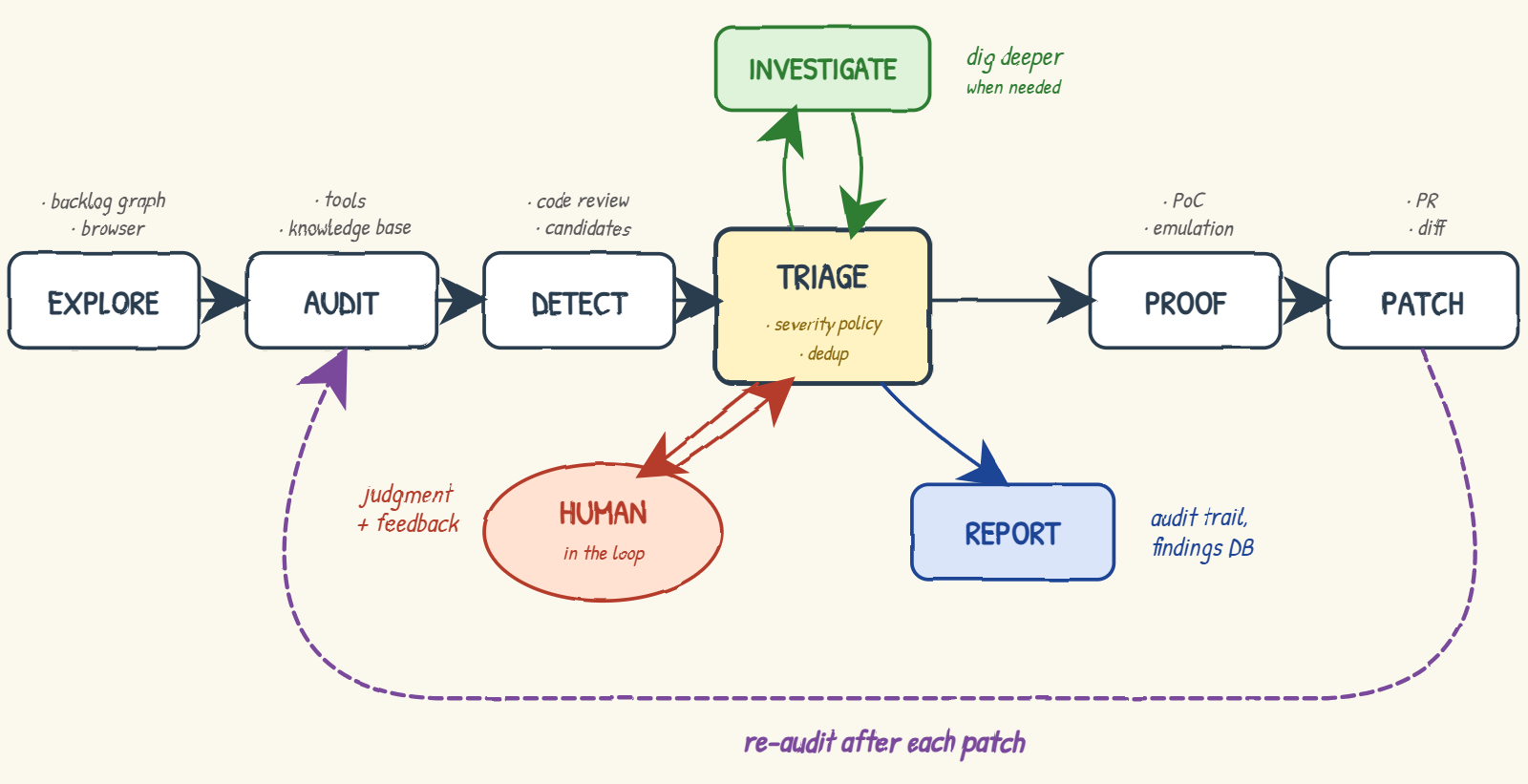
The long road to an AI security harness
1. An assistant assists, it does not drive
If you think your favorite IDE with an AI coding assistant will save you, you are probably wrong.
This does not mean these tools are useless. Quite the opposite. They are impressive. They help engineers move faster, generate code, refactor, explain unfamiliar repositories, and perform useful sanity checks. In many teams, we saw different levels of prompt engineering appear naturally: from the very simple “check if this code is secure” to multi-step prompts with custom skills and repository context.
The answer is: yes, this helps. But only partially. And partial is not enough.
We have seen the same pattern before. Security policies help, but they do not secure a company by themselves. Security training helps, but it does not remove vulnerabilities by itself. In the same way, asking a coding assistant to review code is useful, but it does not create an offensive security capability.
There are two main reasons.
First, assistants tend to stop early. They are optimized to help, answer, and move on. Without adversarial questioning, without several iterations, and without a system that forces deeper investigation, they often do the minimum required to produce a plausible answer. For security, plausibility is dangerous.
Second, context matters. The best development assistants are not good only because of the underlying model. They are good because they inject the right context at the right time: files, symbols, dependencies, diffs, build errors, documentation, and developer intent. But their core task remains development, inside a source repository, with a toolset designed for coding.
2. A prompt is not an agent
Once you realize that the best AI coding assistant was not designed for your security workflows, it is tempting to jump directly to “autonomous agents.” The good news is that the ecosystem is full of frameworks, APIs, orchestration libraries, and examples. The bad news is that a large language model is still, at its core, a function: input in, output out.
Without engineering around it, you will not get an agent.
At best, you will stuff a repository into a large context window, add a final sentence like “is this secure?”, and rediscover the limits of AI-assisted IDEs, only with a more expensive architecture.
This is almost exactly what happened with our first version of Cerberus. We started with the idea of an autonomous pentest agent. The goal was simple: discover new attack surfaces as early as possible and run the kind of battery of tests a pentester would execute manually. Mechanically, repeatedly, and at scale.
The agent stopped after a few minutes. With no meaningful result. Of course. Because a prompt is not an agent.
An agent needs ways to discover, decide, try, fail, remember, listen, analyze, and continue. Just like a human security engineer would need tools, notes, hypotheses, a target, a scope, and feedback from the environment.
3. Prompt engineering, context engineering, tooling engineering
After this first failure, we iterated. The most important lesson was that building useful security agents is not only prompt engineering. It is prompt engineering, context engineering, and tooling engineering.
The first ingredient is the iteration loop. A language model becomes more interesting when its output can feed its next input. This is how it progresses from a single answer to a multi-step investigation. But the loop must be designed. Otherwise, it either stops too soon, repeats itself, or drifts.
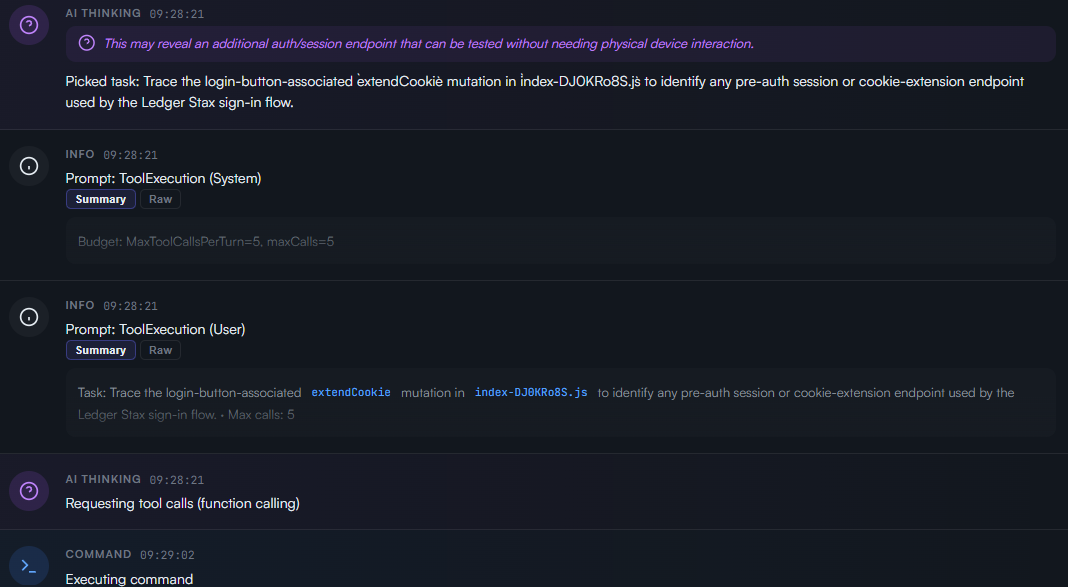
The second ingredient is a backlog. At the beginning, the naive way to provide memory is to re-inject previous messages. That works for a short exchange, but it is not enough for real work. An agent needs to distinguish what it has already done, what it has learned, what remains uncertain, and what should be done next. It needs future tasks, not just past conversations.
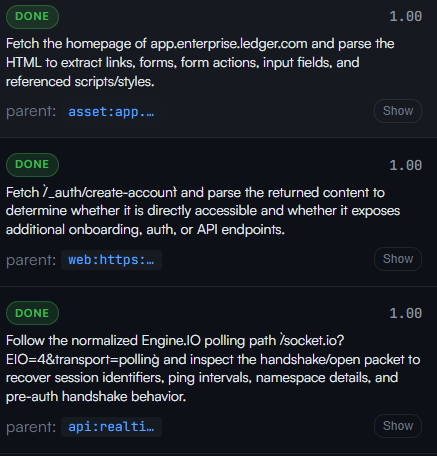
The third ingredient is capabilities. Most modern LLM APIs and agent frameworks provide ways to interact with the outside world. In developer tools, this often appears as MCP integrations or “skills.” But the exact shape of these capabilities matters a lot.
Some capabilities should be functional and structured: add a task to the backlog, declare a potential vulnerability, request a verification scan, attach evidence, update a finding, or create a work item.
Other capabilities should connect the agent to real security tools. The naive approach is to give it shell access. It is also one of the fastest ways to discover two problems at once:
- You open yourself to prompt-injection problems.
- The agent may behave like some of us: it spends its time writing Python, or doing what it knows best, instead of using the security tools already available in a Kali-like distribution.
So tooling engineering matters as much as prompt engineering. You do not only need to tell the model what to do. You need to design the tools that make the right behavior the easiest behavior.
This is where our first two agents emerged inside Cerberus:
- Striker: focused on offensive exploration and pentest-like workflows.
- Sentinel: focused on code security audits and automated review.


4. Agentic systems are still software systems
After playing with Striker for a few hours, another obvious truth came back very quickly: agentic systems are still software systems.
They have cost. They need to scale. They fail. They need observability, queues, retries, budgets, access control, audit trails, and product decisions. The only difference is that a large part of the logic is now non-deterministic.
Cost: we are reliving the cloud moment
A colleague described it perfectly. Remember the first wave of pay-as-you-go cloud services. Suddenly, every action could have a cost. Every environment, every log, every forgotten instance could become a bill. With AI agents, the dynamic is even more aggressive. If you pay more, you can potentially explore more, reason more, verify more, and generate more. But without discipline, you can also burn the budget while producing noise.
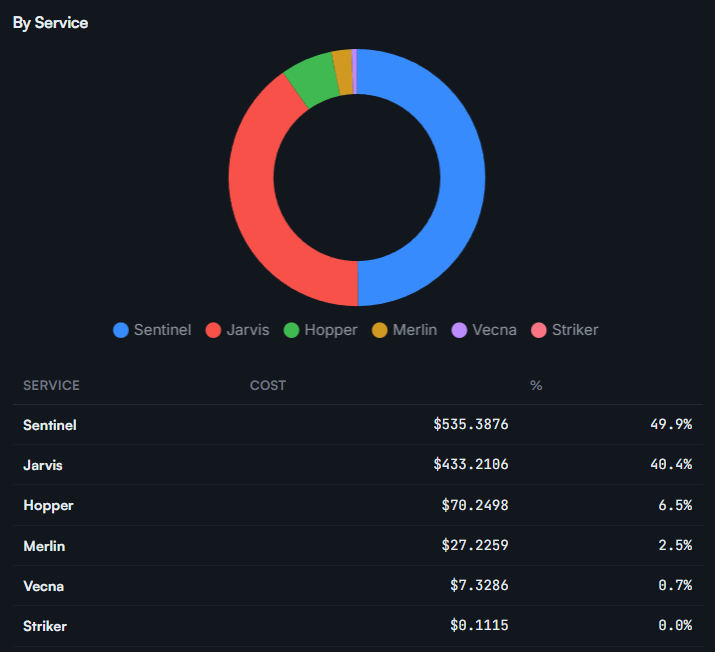
These are not abstract worries. To give an order of magnitude from our own runs, a full code-review scan costs around $3 for a typical repository, but a deep scan on a large codebase can climb to several hundred dollars, so the average lands near $12 per scan precisely because a few deep scans dominate. On the remediation side, generating a patch is cheap: a Merlin fix attempt costs around $0.50 on average. The expensive part of security is never the patch; it is the exploration, verification, and triage that decide whether a patch is even needed. This is exactly the kind of distribution you must measure before you can manage it.
Budget. We made a simple choice: if our ambition is to build a hybrid human and AI security team, then agents need budgets just like human teams have resource constraints. Each agent has a budget. Each month has operational limits. Each workflow must justify its cost.
Optimization. There is no miracle. You need the right model for the right task. For classification, use smaller models. For simple exploration, use moderate reasoning. Keep high or maximum reasoning for the moments where it matters: vulnerability analysis, exploitability reasoning, complex patch validation, or aggregation of conflicting evidence.
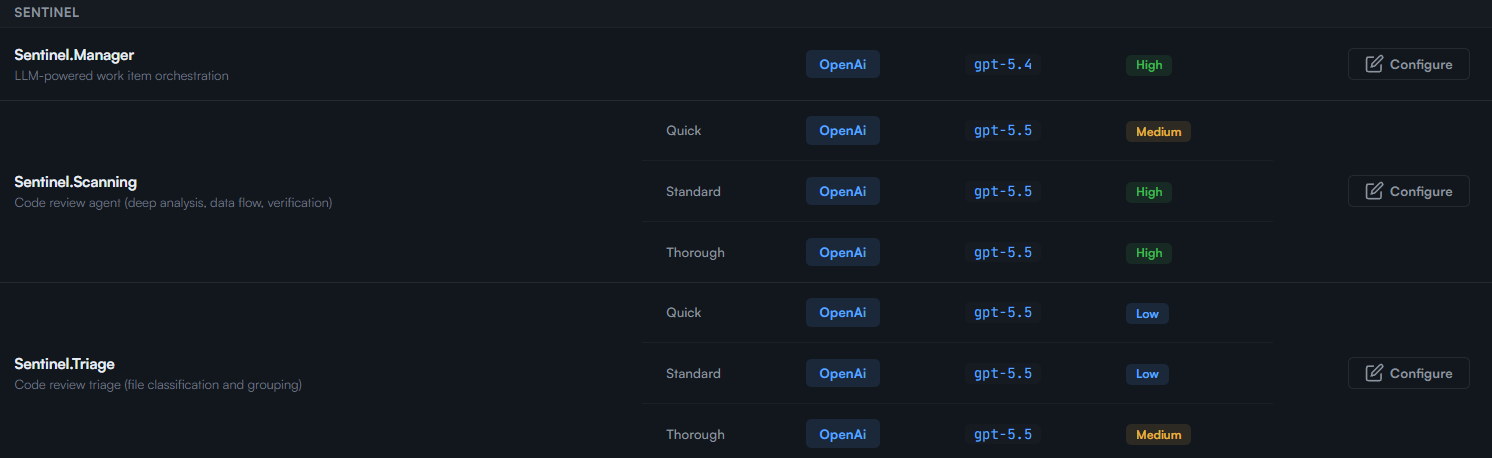
This is also why we are not worried about the next specialized security model. Take something like Mythos: at its core, it is a model, a very capable one focused on finding vulnerabilities. Cerberus is not a competing model. It is the harness around models: the iteration loop, the backlog, the tooling, the triage, the verification, and the budgeting. Our architecture is model-agnostic by design, so the day Mythos, or any future best-in-class model, is the right tool for a task, we do not have to rebuild anything. We simply welcome it as one more agent plugged into the harness.
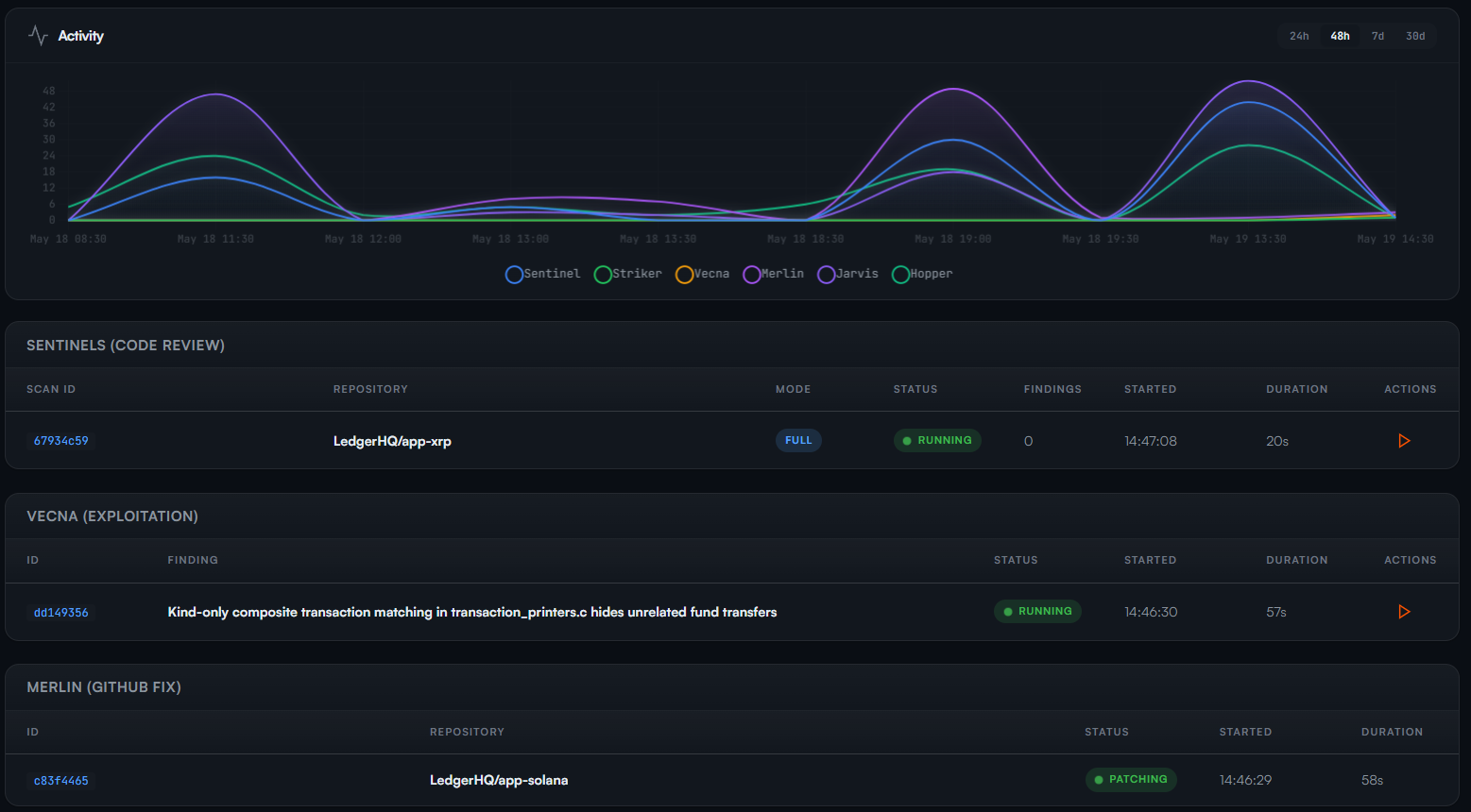
Scalability: use the boring recipes
There is no magic here either. Start with an orchestrator. Use message queues. Split large workflows into smaller tasks. Run agents in parallel when possible. Use more capable agents only when aggregation, arbitration, or deep reasoning is required.
Resilience: repair the boundary between AI and deterministic systems
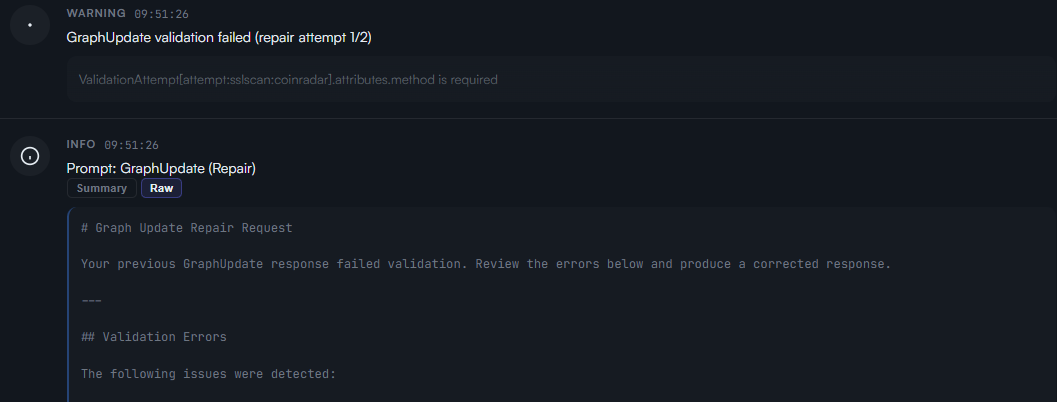
Modern LLM APIs provide structured outputs, often backed by JSON schemas. This helps a lot. But not every business rule can be expressed perfectly in a schema. Sometimes the model returns something that is close, but not acceptable.
Do not give up there. Use the model’s strength to repair its own output. Build repair loops. Explain the constraint violation. Ask for a corrected output. Then only pass clean, validated data to the deterministic system behind it. The AI side can be flexible. The system of record cannot.
5. Mastering non-determinism
For people used to relational databases, business logic, and deterministic workflows, integrating LLMs can be surprising.
The same agent may produce two slightly different reports for the same underlying issue. It may describe a finding differently, use another vulnerable file as the entry point, or assign a different severity depending on the context it explored first.
For example, after multiple Striker iterations, you can end up with results that look like this:
- “SSRF in API TokenGateway.scala, Severity: High”
- “API TokenGateway exposes SSRF through HttpClient.scala, Severity: Critical”
Are these two findings? One finding? A duplicate? A false positive?
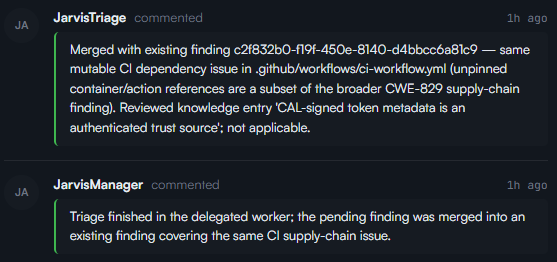
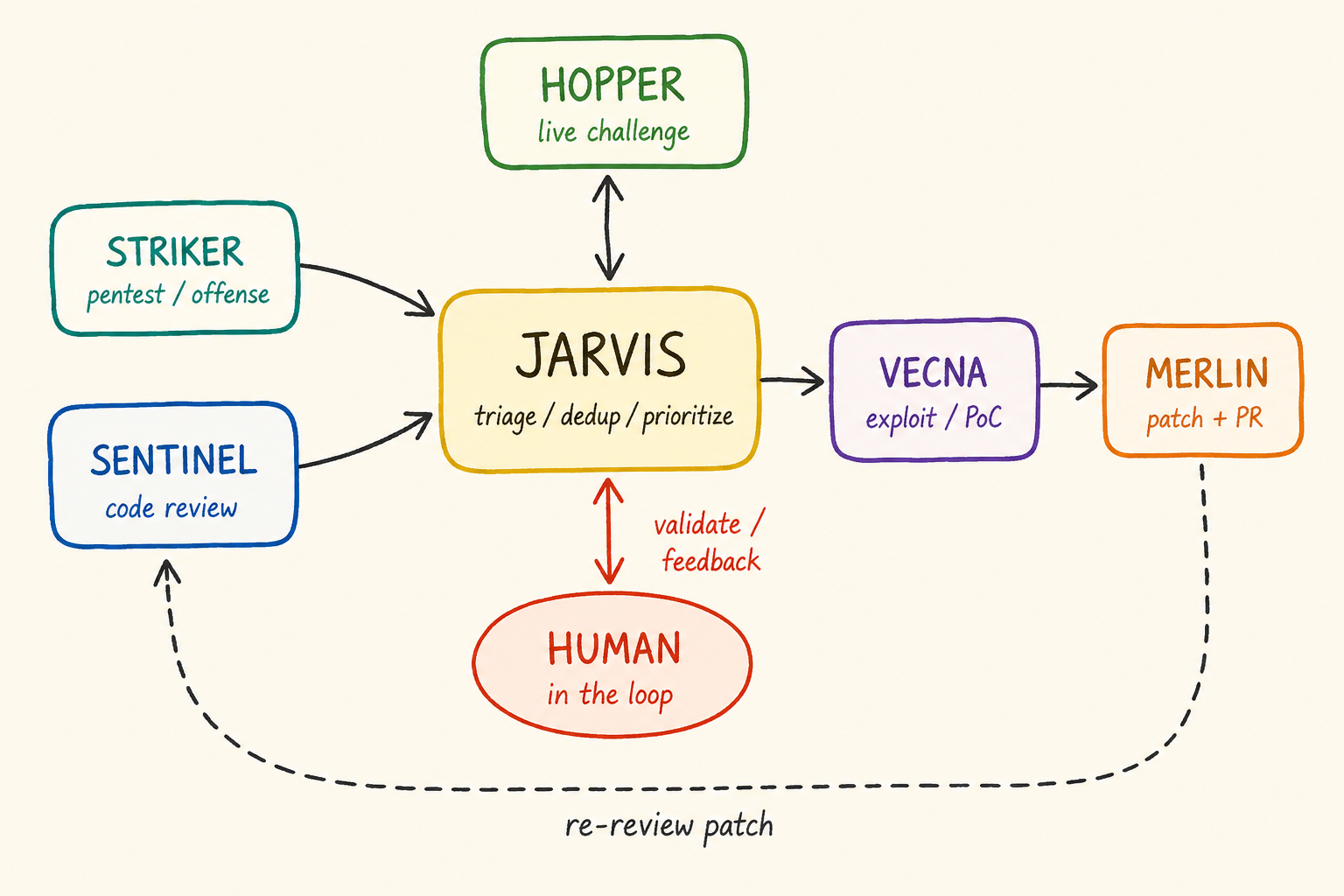
This is where we created Jarvis.

Jarvis became the orchestrator around the vulnerability knowledge base. Its role is to deduplicate, re-analyze, reprioritize, group related findings, and maintain coherence across multiple scans and agents. This is a key lesson: managing AI agents is partly like managing a team.
You need counter-powers. You need cross-validation. You need someone, or something, to challenge the first answer.
Almost every Cerberus flow is built around this principle:
- A finding is always challenged by Jarvis.
- A finding that is not detected by a new scan triggers a second validation scan.
- When a patch is proposed, a new scan verifies the patched code and checks whether the finding is actually solved.
- When an exploit is generated, it is tested multiple times across multiple environments.
Adversarial agents matter. Not adversarial in the “malicious” sense, but adversarial in the security sense: agents designed to challenge findings, verify exploitability, detect duplicates, group similar issues, and avoid flooding humans with noise.
Cross-checks, adversarial review, deduplication, prioritization, verification scans, and audit trails are not optional add-ons. They are the control plane of the system.
6. Reaching the last mile
A security hypothesis is not a finding. “This looks vulnerable” is not enough. A finding has value only when you go to the end.
You need to reproduce it. Exploit it. Understand the impact. Verify the preconditions. Identify the limits. Requalify it if needed. Produce evidence that an engineer can act on.
This is the last mile. It is the hardest part. For that, we created three agents:
Vecna: the end-to-end exploitation agent
Vecna is designed to push a finding as far as possible technically. It must:
- Reproduce the scenario
- Build or adapt a proof of concept
- Test real exploitability
- Identify preconditions
- Measure impact
- Verify whether the finding technically holds, or whether it is simply an internal function that is vulnerable
Hopper: the live challenge assistant
Hopper’s role is more interactive. It supports the analysis in real time, challenges hypotheses, asks the right questions, explores deeper paths, and can help requalify the finding. It helps avoid two traps:
- Accepting a finding too quickly as valid
- Rejecting an idea too quickly because it looks weak at first
Verification needs both: an agent able to execute until the end, and an assistant able to challenge the reasoning live.
Merlin: the patch wizard
When Vecna delivers a PoC without modifying the main codebase and returns the status “exploitable,” there is no doubt anymore. With the progress of LLMs in code generation, the last mile cannot stop at reporting. It must also cover remediation.
Merlin can patch. Of course, we ask its friend Sentinel, the code-review agent, to verify whether the patch really covers the vulnerability. Then Merlin can open the pull request, monitor the PR, observe the CI, and adjust if needed. Your AI security harness must embrace your AI SDLC.

The loop becomes complete: Detect. Verify. Exploit. Patch. Review. Monitor.
7. Turning specialized agents into a team
A team is not a collection of experts sitting next to each other. A team is the ability to discuss, delegate, synchronize, disagree, commit, and communicate. Agents need the same kind of structure.
How do you make Striker, Sentinel, Jarvis, Vecna, Hopper, and Merlin work together without turning the platform into a collection of smart scripts calling each other randomly?
First answer: create meta-agents, or manager agents. Their job is to receive a task, understand the objective, qualify its scope, split the work, launch the right tasks, follow progress, consolidate the results, and arbitrate when needed.
Second answer: connect them together. Each manager has its own scope of responsibility. But it must also be able to delegate to other agents through structured objects: tickets, work items, tasks. Agents should not simply call each other in an uncontrolled chain. They should pass work through a common abstraction. It gives you scope, delegation, traceability, consolidation, and arbitration.
But it also creates a new problem: how do you write the prompt of a manager? Two extremes do not work:
- If the prompt is too short, the manager invents behavior. It may delegate in strange ways, exceed its scope, or optimize for the wrong objective.
- If the prompt is too long, it becomes pseudo-code written in natural language. It is hard to read, hard to maintain, and brittle.
The real challenge is finding the right level of abstraction. It is almost like managing engineers: don’t micromanage, give autonomy, but clarify the cap.
8. Integrating the agent team into the human team
An agentic security team cannot live alone. If it stays outside the company workflow, it is just a demo. Maybe an impressive demo. But still a demo.
To become useful, it must live where security work already happens: Slack, tickets, repositories, policies, code reviews, incident processes, and engineering discussions.
This is where the “human in the loop” becomes real:
- Communication. A Slack communication agent can interact with teams, notify the right channels, ask questions, request validation, and surface useful information where humans already work.
- Policy integration. Internal security documentation, guidelines, and policies should not remain passive documents. They should become active inputs for the platform. If the security handbook evolves, the system should be able to derive or improve controls from it.
- Tool integration. APIs and MCP servers can connect agents to repositories, ticketing systems, scans, findings, policies, and knowledge bases.
- Knowledge improvement. The knowledge base becomes a central asset. It feeds prompts, structures context, captures past decisions, records false-positive justifications, and improves future workflows.
Does it actually work? Real findings
A platform like this is only worth describing if it produces real results. It does. Cerberus has already reported exploitable vulnerabilities to upstream maintainers, following responsible disclosure: when a finding is realistically exploitable, we report it privately through the project’s security channel and follow their coordinated-disclosure process; for lower-impact issues, we open a public issue or pull request so the conversation happens openly with maintainers.
Here is a sample of what the agent team has surfaced:
| Project | Date | Vulnerability | Severity | Reference |
|---|---|---|---|---|
| Sandboxie-Plus | 2026-05-22 | APC injection sandbox escape via unvalidated GuiServer hook registration | High (CVSS 7.7) | CVE-2026-45313 |
| Clawvisor | 2026-04-24 | Cross-tenant adapter overwrite in generated adapter installation | Critical | PR #302 |
| Yubico (libfido2, python-fido2, YubiKey Manager) | 2026-04-15 | DLL search-path hijack on Windows | High (CVSS 7.0) | CVE-2026-40947 |
| KDE Kleopatra | 2026-04-08 | Local privilege escalation on Windows via single-instance mechanism | High | CVE-2026-41527 |
| Nethermind | 2026-04-03 | Duplicate-signature quorum bypass in XDC vote aggregation | Critical | PR #11027 |
| Wasabi Wallet | 2026-03-16 | OS command injection in URL opener via crafted “Read More” link | High | Issue #14410 |
| BTCPay Server | 2026-03-13 to 03-15 | 6 access-control & tampering issues: IDOR, cross-store/cross-tenant escalation, plan/price tampering | High to Critical | Commits |
These range from memory-safety and privilege-escalation issues to access-control and consensus bugs across very different stacks: C, .NET, Scala, and more. The full and updated list lives at github.com/Donjon-Cerberus.
But not everything is lost
Security has always been a long game between cat and mouse. But today, adopting a cat costs almost nothing, and cats are everywhere.
Attackers will use AI. Some will use it badly and generate noise. Some will use it well and scale real offensive work. Security teams cannot afford to treat this as a future problem.
They must build their own AI capabilities, but also change the foundations they build on. AI security harnesses can help find, verify, prioritize, and fix vulnerabilities faster. But the best vulnerability is still the one that cannot exist.
This means changing development habits too:
-
Memory-safe languages must become the default choice wherever the platform and constraints allow it. For Ledger, 2026 will be an important transition year, with a strong reprioritization of Rust over C for device applications. This is not because C suddenly becomes bad overnight. It is because the cost of mistakes is changing. Rust does not remove the need for security engineering, but it reduces a major class of vulnerabilities by construction.
-
Formal verifications also need to become more practical and more common. Not everything can be formally proven, and not every proof is worth the cost. But for critical components (protocols, parsers, cryptographic logic, and security invariants), proofs can shift part of the discussion from “the AI did not find a bug” to “this property is guaranteed under explicit assumptions.”
This is the direction we need: more offensive automation, more verification, better engineering foundations, and stronger evidence.
To recap how the pieces fit together: Striker and Sentinel explore and review, Jarvis triages and arbitrates, Hopper challenges hypotheses live, Vecna proves exploitability, and Merlin patches, with a human in the loop at the center and every patch sent back for re-review. None of them works alone; the value comes from the way they pass work to each other.
AI will not remove the need for security expertise. It raises the bar for everyone. The teams that adapt will gain leverage. The teams that wait for the perfect model, the perfect framework, or the perfect moment will discover that the attackers did not wait.
No fight, no chance.
By Vincent Bouzon, Ledger Donjon