
Non-Profiled Deep Learning Side-Channel Attacks on ML-KEM
Part 2 of our series on side-channel attacks against post-quantum cryptography: we break the CRYSTALS ML-KEM reference implementation with a non-profiled deep learning attack — no clone device, no leakage model.
Part 2 of the Ledger Donjon series on side-channel attacks against post-quantum cryptography.

Before you dive in
In our previous post, the Donjon team showed that a textbook Correlation Power Analysis (CPA) attack recovers the ML-KEM secret key from the pqm4 implementation of Kyber on an STM32F4, in roughly 40 EM traces collected in under a minute. The routine targeted in that attack was the hand-written ARM assembly multiplier poly_frombytes_mul.
In this post we move one step upstream. Instead of an optimised downstream port, we target the official CRYSTALS reference implementation, and specifically the basemul function — the atomic coefficient-pair multiplication on top of which every Kyber port (including pqm4) is built. The implementation is unprotected: no masking, no shuffling, and no desynchronisation.
CPA is a linear statistical test built around a Hamming-weight leakage model. It works beautifully on an unprotected target because the chip happens to leak the way the model assumes. The point of this post is to show that the same target can also be broken with non-profiled deep learning, in the spirit of Timon’s TCHES 2019/2 paper on AES. No clone device, no profiling phase: a small neural network is trained directly on the attack traces, once per key hypothesis, and the correct key is the one under which the network actually learns.
Concretely, our non-profiled neural attack recovers the secret coefficient with about 400 EM traces — an order of magnitude more than CPA, but still acquired in a few minutes and with no commitment to a specific leakage model.
Where we left off, and what changes this time
In Part 1, we placed an EM probe over an STM32F4 running pqm4’s ML-KEM decapsulation and zoomed in on the assembly-optimised polynomial multiplier poly_frombytes_mul. That routine computes, coefficient-pair by coefficient-pair, the NTT-domain product of the secret key a = (a0, a1) with attacker-controlled ciphertext halves b = (b0, b1):
r0 = (a0 * b0) + (a1 * b1 * zeta)
r1 = (a0 * b1) + (a1 * b0)By choosing ciphertexts with one of the two halves forced to zero, we reduced the joint guess space from 2^24 down to 2^12, correlated EM traces against the Hamming weight of the candidate intermediate, and reached key recovery in about 40 traces.
Two things change this time:
- We drop pqm4 and attack the official CRYSTALS reference implementation directly, compiled from pq-crystals/kyber.
- Inside that reference, we sharpen the target from the wrapper
poly_basemul_montgomerydown to the atomic routine it calls in a loop:basemul, defined inref/ntt.c.
What changes is the statistic that distinguishes the correct key. CPA used Pearson correlation; we replace it with a small neural network — an alternative to CPA and a promising method against designs with countermeasures.
What remains identical to Part 1: the implementation is unprotected (no masking, no shuffling, no desynchronisation).
The target: basemul in the CRYSTALS reference implementation
ML-KEM, standardized in FIPS 203 in August 2024, is the post-quantum KEM derived from CRYSTALS-Kyber. It operates on polynomials in the ring R_q = Z_q[X] / (X^256 + 1) with q = 3329. The Decaps procedure recovers a message from a ciphertext using the long-term secret s; inside it, the secret is multiplied — coefficient pair by coefficient pair, in the NTT domain — against attacker-observable values derived from the ciphertext.
The reference C code for that multiplication is shipped by the CRYSTALS team in the ref/ tree. The relevant call chain inside Decaps is:
indcpa_decinref/indcpa.ccallspolyvec_basemul_acc_montgomeryinref/polyvec.c, which loops over the components of the secret vector and callspoly_basemul_montgomeryinref/poly.c, which itself loops over 64 coefficient blocks of size 4 and callsbasemulinref/ntt.c, the atomic operation we attack.
The basemul function is exactly the equation we recalled from Part 1, written in clean portable C:
// pq-crystals/kyber/ref/ntt.c
void basemul(int16_t r[2], const int16_t a[2], const int16_t b[2], int16_t zeta)
{
r[0] = fqmul(a[1], b[1]);
r[0] = fqmul(r[0], zeta);
r[0] += fqmul(a[0], b[0]);
r[1] = fqmul(a[0], b[1]);
r[1] += fqmul(a[1], b[0]);
}Here a represents the secret key in Number Theoretic Transform (NTT) form, while b denotes a ciphertext-dependent variable, also represented in the NTT domain.
Setup and leakage detection
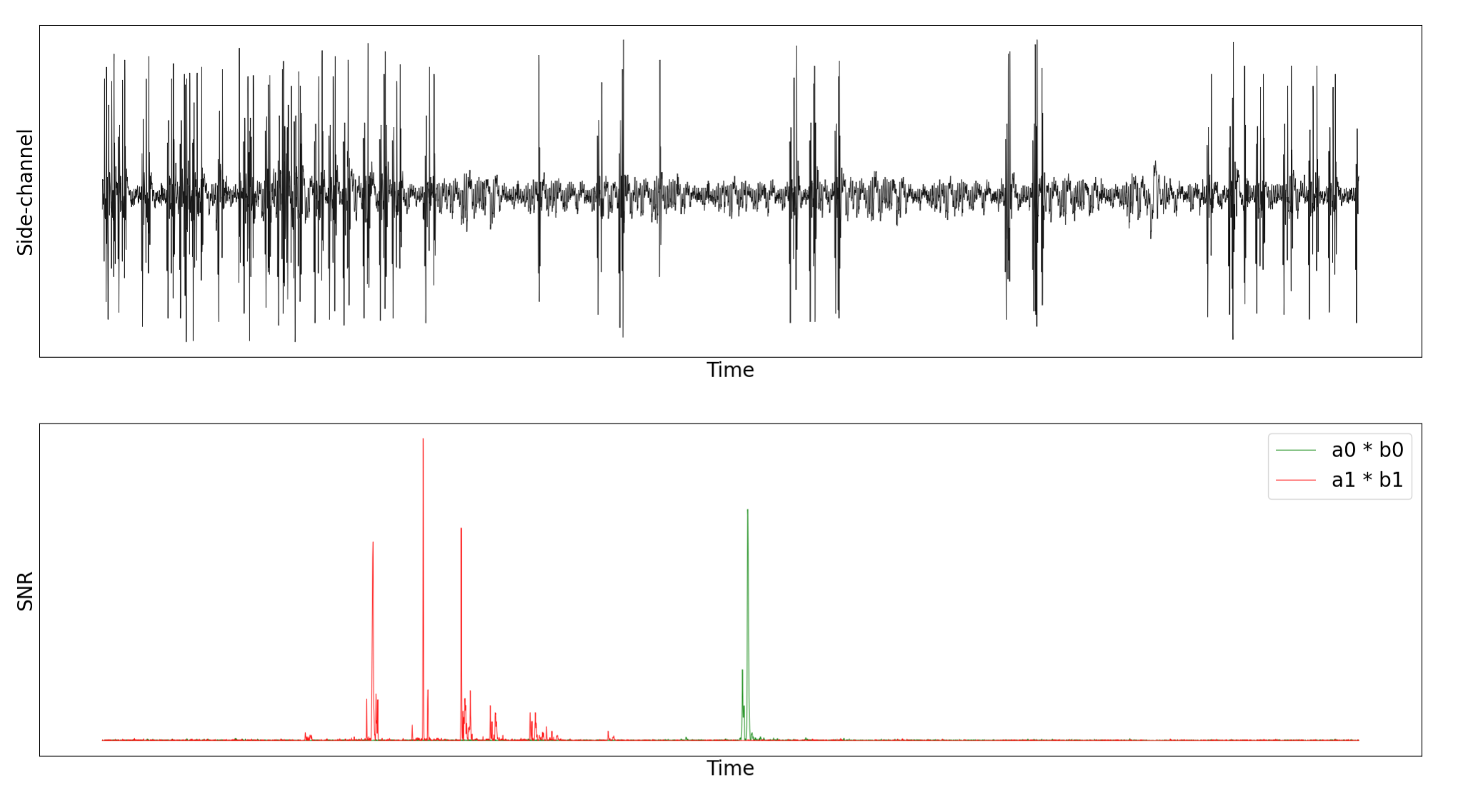
The experimental setup mirrored that detailed in the previous blog post, this time running the reference implementation. Electromagnetic (EM) traces were acquired, specifically targeting the basemul operation. We then performed SNR-based leakage detection to identify the time points within the EM traces corresponding to the manipulation of the intermediate values a1 * b1 and a0 * b0. The SNR calculation was based on the Hamming weight of the multiplication result.
The figure below shows both the captured EM trace and the SNR for the intermediate values, clearly indicating that the design leaks, as represented by the green and red curves. Consequently, the non-profiled deep learning (DL) attack is executed on the time instances exhibiting the maximum SNR values.
Deep-learning side-channel attacks come in two flavours, and the distinction matters
Profiled attacks assume the attacker owns a clone device identical to the victim, on which they can run the cryptographic algorithm with known secret keys. They use that clone to capture tens of thousands of labelled traces and train a classifier that predicts a secret intermediate from a trace. At attack time, the trained classifier is applied to traces from the victim’s device.
Non-profiled attacks need no clone device. The attacker only has the victim’s device and the ability to feed it chosen ciphertexts — exactly the setting of our Part 1 CPA attack. Classical non-profiled SCA (CPA, DPA) handles this by making a key hypothesis, computing a hypothesis-dependent intermediate value for each trace, and testing whether some fixed statistic separates the correct hypothesis from the wrong ones. The price you pay for not needing a clone device is that the leakage model has to be specified upfront; for CPA, it is usually the Hamming weight.
Timon’s TCHES paper “Non-Profiled Deep Learning-based Side-Channel Attacks with Sensitivity Analysis” showed how to extend deep learning to that setting on AES, without ever needing a clone device. The trick is to let the network play the role of the statistic, not the role of the labelled classifier. Concretely, for each candidate key k:
-
For every captured trace, a hypothesis-dependent label is computed. This label corresponds to the intermediate value traditionally used in CPA, but is re-purposed as a training objective for the neural network rather than a conventional statistical metric:
L_K = HW(f(s, ciphertext))where
L_Kis the label-based leakage,HWis the Hamming weight,fis thebasemul-based function, andsis the secret key. -
A neural network is trained using the
(traces, L_K)pairs corresponding to each brute-forced secret key values. -
The correct key hypothesis is the one under which the neural network achieves the highest accuracy (or the lowest loss).
This methodology was shown to break both protected and unprotected AES.
Non-profiled deep learning on basemul
Step 1 — Capture. We acquire 400 EM traces while the chip executes basemul on the same secret coefficient pair a = (a0, a1) and 400 chosen ciphertext pairs.
Step 2 — Hypotheses. For each candidate value a1 ∈ {0, 1, ..., q-1} and each captured trace, we compute the Hamming weight of the predicted intermediate value:
label = HW(fqmul(a1, b1))Step 3 — Neural network. We selected the following Multi-Layer Perceptron (MLP) model for training:
def mlp_non_profiling(len_samples: int) -> keras.Model:
model = Sequential()
model.add(Input(shape=(len_samples,)))
model.add(Dense(20, activation="relu"))
model.add(Dense(10, activation="relu"))
model.add(Dense(17, activation="softmax"))
model.compile(optimizer="adam", loss="mean_squared_error", metrics=["accuracy"])
return modelStep 4 — Train, once per hypothesis. For each hypothesis, we train the model and save the accuracy so we can later pick the correct key:
profile_engine = NonProfile(leakage_model=leakage_model)
for index, guess in enumerate(tqdm(key_range)):
set_seed(SEED + index) # Different but reproducible per guess
acc[index] = profile_engine.train(
model=mlp_non_profiling(x_train.shape[1]),
x_train=x_train,
metadata=metadata,
guess=guess,
hist_acc="accuracy",
num_classes=17,
epochs=EPOCHS,
batch_size=1000,
verbose=0,
shuffle=True, # Explicit; order is reproducible due to seed
)We repeated this scenario to attack a0 as well, using:
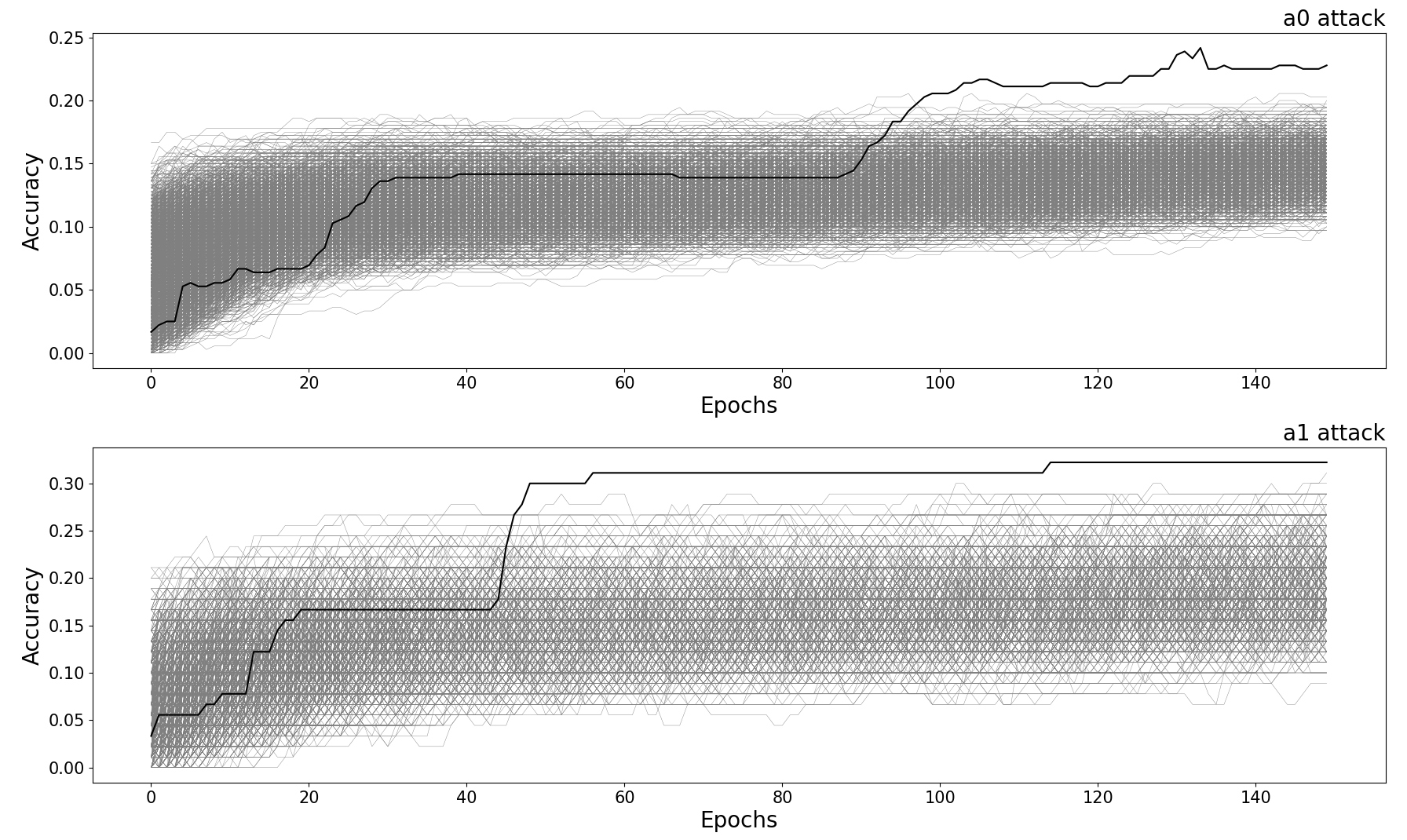
label = HW(fqmul(a0, b0))The execution of this attack used our open-source tool, scadl. Compared to the accuracy of the incorrect key hypotheses, the correct key hypothesis yielded the highest accuracy for both a0 and a1, as shown in the figure below. Correct key guesses are plotted in black, and incorrect key guesses in gray.
Conclusion
This study successfully demonstrated a non-profiled deep learning side-channel attack targeting the basemul function within the official CRYSTALS ML-KEM reference implementation. Using a compact neural network trained directly on captured electromagnetic traces, we established that secret coefficients are recoverable without a clone device and without a pre-defined leakage model.
While this model-agnostic methodology required approximately 400 EM traces — an order of magnitude more than classical CPA — it underscores the significant vulnerability of the post-quantum cryptography reference implementation when deployed without protective countermeasures such as masking or shuffling. This method is also slated for application in future work against protected implementations.
Karim M. Abdellatif, Ph.D. & Alain Magazin — Ledger Donjon